The goal of this post is motivated by the desire to sentiment analysis and text classification of Amazon reviews in English laguage.
Data Preparation
Amazon Reviews Dataset
This dataset contains several million reviews of Amazon customer reviews and star ratings for sentiment analysis. Each review is assigned a label indicating whether this is a positive (4-5 stars) or a negative (1-2 stars) review. No neutral reviews are included. Most of the reviews are in English. Since the data are generated by Amazon users, they can contain lots of typos, strange spellings and other variations.
Since the texts are given in a compressed format, we have to decode the file and read the text line by line. The first word of each line is the label and the rest is the comment.
import bz2
train_file = bz2.BZ2File('train.ft.txt.bz2')
test_file = bz2.BZ2File('test.ft.txt.bz2')
train_file_lines = train_file.readlines()
test_file_lines = test_file.readlines()
del train_file, test_file
# Convert from raw binary strings to strings that can be parsed
train_file_lines = [x.decode('utf-8') for x in train_file_lines]
test_file_lines = [x.decode('utf-8') for x in test_file_lines]
The first thing to do is to transform all texts into lowercase. Next, we can remove non-word characters and letters with accents, since they don’t occur often in the dataset and also do not play a great role in determining the sentiment.
import re
train_labels = [0 if x.split(' ')[0] == '__label__1' else 1 for x in train_file_lines]
train_sentences = [x.split(' ', 1)[1][:-1].lower() for x in train_file_lines]
for i in range(len(train_sentences)):
train_sentences[i] = re.sub('\d','0',train_sentences[i])
test_labels = [0 if x.split(' ')[0] == '__label__1' else 1 for x in test_file_lines]
test_sentences = [x.split(' ', 1)[1][:-1].lower() for x in test_file_lines]
for i in range(len(test_sentences)):
test_sentences[i] = re.sub('\d','0',test_sentences[i])
for i in range(len(train_sentences)):
if 'www.' in train_sentences[i] or 'http:' in train_sentences[i] or 'https:' in train_sentences[i] or '.com' in train_sentences[i]:
train_sentences[i] = re.sub(r"([^ ]+(?<=\.[a-z]{3}))", "<url>", train_sentences[i])
for i in range(len(test_sentences)):
if 'www.' in test_sentences[i] or 'http:' in test_sentences[i] or 'https:' in test_sentences[i] or '.com' in test_sentences[i]:
test_sentences[i] = re.sub(r"([^ ]+(?<=\.[a-z]{3}))", "<url>", test_sentences[i])
After preprocessing, we can delete unused read lines objects to save memory
del train_file_lines, test_file_lines
import gc
gc.collect()
111
len(train_sentences), len(test_sentences)
(3600000, 400000)
train_sentences[0]
'stuning even for the non-gamer: this sound track was beautiful! it paints the senery in your mind so well i would recomend it even to people who hate vid. game music! i have played the game chrono cross but out of all of the games i have ever played it has the best music! it backs away from crude keyboarding and takes a fresher step with grate guitars and soulful orchestras. it would impress anyone who cares to listen! ^_^'
train_iter = list(zip(train_labels, train_sentences))
test_iter = list(zip(test_labels, test_sentences))
Prepare data processing pipelines
Pytorch provides a convenient way to convert text to tokenizer, which is a useful format for deep learning.
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
tokenizer = get_tokenizer('basic_english')
def yield_tokens(data_iter):
for _, text in data_iter:
yield tokenizer(text)
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])
vocab(['here', 'is', 'an', 'example'])
[197, 12, 50, 712]
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: int(x)
text_pipeline('here is the an example')
[197, 12, 2, 50, 712]
label_pipeline('10')
10
Generate data batch and iterator
import torch
from torch.utils.data import DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def collate_batch(batch):
label_list, text_list, offsets = [], [], [0]
for (_label, _text) in batch:
label_list.append(label_pipeline(_label))
processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)
text_list.append(processed_text)
offsets.append(processed_text.size(0))
label_list = torch.tensor(label_list, dtype=torch.int64)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
text_list = torch.cat(text_list)
return label_list.to(device), text_list.to(device), offsets.to(device)
dataloader = DataLoader(train_iter, batch_size=8, shuffle=False, collate_fn=collate_batch)
Split dataset
train_iter = list(zip(train_labels, train_sentences))
test_iter = list(zip(test_labels, test_sentences))
i = 0
for label, text in train_iter:
i += 1
print(label, "||", text)
if (i == 12): break
1 || stuning even for the non-gamer: this sound track was beautiful! it paints the senery in your mind so well i would recomend it even to people who hate vid. game music! i have played the game chrono cross but out of all of the games i have ever played it has the best music! it backs away from crude keyboarding and takes a fresher step with grate guitars and soulful orchestras. it would impress anyone who cares to listen! ^_^
1 || the best soundtrack ever to anything.: i'm reading a lot of reviews saying that this is the best 'game soundtrack' and i figured that i'd write a review to disagree a bit. this in my opinino is yasunori mitsuda's ultimate masterpiece. the music is timeless and i'm been listening to it for years now and its beauty simply refuses to fade.the price tag on this is pretty staggering i must say, but if you are going to buy any cd for this much money, this is the only one that i feel would be worth every penny.
1 || amazing!: this soundtrack is my favorite music of all time, hands down. the intense sadness of "prisoners of fate" (which means all the more if you've played the game) and the hope in "a distant promise" and "girl who stole the star" have been an important inspiration to me personally throughout my teen years. the higher energy tracks like "chrono cross ~ time's scar~", "time of the dreamwatch", and "chronomantique" (indefinably remeniscent of chrono trigger) are all absolutely superb as well.this soundtrack is amazing music, probably the best of this composer's work (i haven't heard the xenogears soundtrack, so i can't say for sure), and even if you've never played the game, it would be worth twice the price to buy it.i wish i could give it 0 stars.
1 || excellent soundtrack: i truly like this soundtrack and i enjoy video game music. i have played this game and most of the music on here i enjoy and it's truly relaxing and peaceful.on disk one. my favorites are scars of time, between life and death, forest of illusion, fortress of ancient dragons, lost fragment, and drowned valley.disk two: the draggons, galdorb - home, chronomantique, prisoners of fate, gale, and my girlfriend likes zelbessdisk three: the best of the three. garden of god, chronopolis, fates, jellyfish sea, burning orphange, dragon's prayer, tower of stars, dragon god, and radical dreamers - unstealable jewel.overall, this is a excellent soundtrack and should be brought by those that like video game music.xander cross
1 || remember, pull your jaw off the floor after hearing it: if you've played the game, you know how divine the music is! every single song tells a story of the game, it's that good! the greatest songs are without a doubt, chrono cross: time's scar, magical dreamers: the wind, the stars, and the sea and radical dreamers: unstolen jewel. (translation varies) this music is perfect if you ask me, the best it can be. yasunori mitsuda just poured his heart on and wrote it down on paper.
1 || an absolute masterpiece: i am quite sure any of you actually taking the time to read this have played the game at least once, and heard at least a few of the tracks here. and whether you were aware of it or not, mitsuda's music contributed greatly to the mood of every single minute of the whole <url>posed of 0 cds and quite a few songs (i haven't an exact count), all of which are heart-rendering and impressively remarkable, this soundtrack is one i assure you you will not forget. it has everything for every listener -- from fast-paced and energetic (dancing the tokage or termina home), to slower and more haunting (dragon god), to purely beautifully composed (time's scar), to even some fantastic vocals (radical <url>s is one of the best videogame soundtracks out there, and surely mitsuda's best ever. ^_^
0 || buyer beware: this is a self-published book, and if you want to know why--read a few paragraphs! those 0 star reviews must have been written by ms. haddon's family and friends--or perhaps, by herself! i can't imagine anyone reading the whole thing--i spent an evening with the book and a friend and we were in hysterics reading bits and pieces of it to one another. it is most definitely bad enough to be entered into some kind of a "worst book" contest. i can't believe amazon even sells this kind of thing. maybe i can offer them my 0th grade term paper on "to kill a mockingbird"--a book i am quite sure ms. haddon never heard of. anyway, unless you are in a mood to send a book to someone as a joke---stay far, far away from this one!
1 || glorious story: i loved whisper of the wicked saints. the story was amazing and i was pleasantly surprised at the changes in the book. i am not normaly someone who is into romance novels, but the world was raving about this book and so i bought it. i loved it !! this is a brilliant story because it is so true. this book was so wonderful that i have told all of my friends to read it. it is not a typical romance, it is so much more. not reading this book is a crime, becuase you are missing out on a heart warming story.
1 || a five star book: i just finished reading whisper of the wicked saints. i fell in love with the caracters. i expected an average romance read, but instead i found one of my favorite books of all time. just when i thought i could predict the outcome i was shocked ! the writting was so descriptive that my heart broke when julia's did and i felt as if i was there with them instead of just a distant reader. if you are a lover of romance novels then this is a must read. don't let the cover fool you this book is spectacular!
1 || whispers of the wicked saints: this was a easy to read book that made me want to keep reading on and on, not easy to put down.it left me wanting to read the follow on, which i hope is coming soon. i used to read a lot but have gotten away from it. this book made me want to read again. very enjoyable.
0 || the worst!: a complete waste of time. typographical errors, poor grammar, and a totally pathetic plot add up to absolutely nothing. i'm embarrassed for this author and very disappointed i actually paid for this book.
1 || great book: this was a great book,i just could not put it down,and could not read it fast enough. boy what a book the twist and turns in this just keeps you guessing and wanting to know what is going to happen next. this book makes you fall in love and can heat you up,it can also make you so angery. this book can make you go throu several of your emotions. this is a quick read romance. it is something that you will want to end your day off with if you read at night.
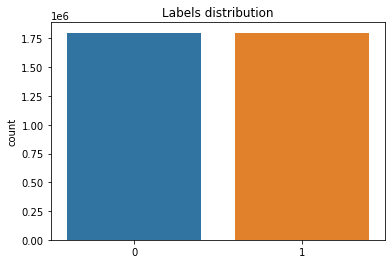
import matplotlib.pyplot as plt
import seaborn as sns
sns.countplot(train_labels)
plt.title('Labels distribution')
We are going to set aside a small part of the training set for validation.
# Hyperparameters
EPOCHS = 10 # epoch
LR = 5 # learning rate
BATCH_SIZE = 64 # batch size for training
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
total_accu = None
train_dataset = to_map_style_dataset(train_iter)
test_dataset = to_map_style_dataset(test_iter)
num_train = int(len(train_dataset) * 0.95)
split_train_, split_valid_ = \
random_split(train_dataset, [num_train, len(train_dataset) - num_train])
train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
Define Model
from torch import nn
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super(TextClassificationModel, self).__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)
num_class = len(set([label for (label, text) in train_iter]))
vocab_size = len(vocab)
emsize = 64
model = TextClassificationModel(vocab_size, emsize, num_class).to(device)
Define training pipeline
import time
def train(dataloader):
model.train()
total_acc, total_count = 0, 0
log_interval = 500
start_time = time.time()
for idx, (label, text, offsets) in enumerate(dataloader):
optimizer.zero_grad()
predicted_label = model(text, offsets)
loss = criterion(predicted_label, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1)
optimizer.step()
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
if idx % log_interval == 0 and idx > 0:
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches '
'| accuracy {:8.3f}'.format(epoch, idx, len(dataloader),
total_acc/total_count))
total_acc, total_count = 0, 0
start_time = time.time()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
def evaluate(dataloader):
model.eval()
total_acc, total_f1, total_roc = 0, 0, 0,
total_count = len(dataloader)
with torch.no_grad():
for idx, (label, text, offsets) in enumerate(dataloader):
predicted_label = model(text.to(device), offsets)
loss = criterion(predicted_label, label)
total_acc += accuracy_score(predicted_label.argmax(1).cpu(),label.cpu())
total_f1 += f1_score(predicted_label.argmax(1).cpu(),label.cpu())
total_roc += roc_auc_score(predicted_label.argmax(1).cpu(),label.cpu())
return total_acc/total_count, total_f1/total_count, total_roc/total_count
for epoch in range(1, EPOCHS + 1):
epoch_start_time = time.time()
train(train_dataloader)
accu_val,_,_ = evaluate(valid_dataloader)
if total_accu is not None and total_accu > accu_val:
scheduler.step()
else:
total_accu = accu_val
print('-' * 59)
print('| end of epoch {:3d} | time: {:5.2f}s | '
'valid accuracy {:8.3f} '.format(epoch,
time.time() - epoch_start_time,
accu_val))
print('-' * 59)
Evaluation
Once the model is done with the training, we can check the model performance on the test set.
from sklearn.metrics import f1_score, roc_auc_score, accuracy_score
print('Evaluating model...')
accu_test, f1_test, toc_test = evaluate(test_dataloader)
print('test accuracy {:8.3f}, test f1 {:8.3f}, test roc auc score {:8.3f}'.format(accu_test, f1_test, toc_test))
Evaluating model...
test accuracy 0.911, test f1 0.910, test roc auc score 0.911
We can test the model on random reviews:
labels = {0: "Negative" , 1: "Positive"}
def predict(text, text_pipeline):
with torch.no_grad():
text = torch.tensor(text_pipeline(text))
output = model(text, torch.tensor([0]))
return output.argmax(1).item()
model = model.to("cpu")
reviews = ["Not as expected",
"Qualitatively, the shoe is an insult and it is understandable that other buyers believed they had bought a fake.",
"The first time I have seen such amazing pen",
"Buy these shoes for my husband for the second time. Perfect fit, look great. You can combine them to many things.",
"Operation and care good, taste good, quality milk foam deficient - unfortunately also not individually selectable.", # a neutral review
"Perhaps I am also extremely demanding preconditioned by my honorable Jura Impressa Z5.",]
for review in reviews:
print(review)
print("This is a %s review" %labels[predict(review, text_pipeline)])
Not as expected
This is a Negative review
Qualitatively, the shoe is an insult and it is understandable that other buyers believed they had bought a fake.
This is a Negative review
The first time I have seen such amazing pen
This is a Positive review
Buy these shoes for my husband for the second time. Perfect fit, look great. You can combine them to many things.
This is a Positive review
Operation and care good, taste good, quality milk foam deficient - unfortunately also not individually selectable.
This is a Negative review
Perhaps I am also extremely demanding preconditioned by my honorable Jura Impressa Z5.
This is a Negative review
We got an accuracy score of 91%, which is pretty good. Training was easy, but the most challenging task is the data preprocessing.